Dive into the network regression affection to network service
In recent work my team devoted in a cross region data replication solution, a simplified abstraction of the workload is as follows

The gRPC service and downstream MySQL are located in different AWS regions(such as one in EU, and the other one in US East), and the average network latency between these two regions is 70ms. We have a choice to deploy the data transfer service in either gRPC service side or downstream MySQL side. After a series of tests, we observed that deploying data transfer service in the downstream(the downstream MySQL) side has much larger throughput than deploying it in the upstream(the gRPC service) side. This article will analyze the root cause from both benchmark result and principle analysis, try to find potential solutions and give advice about such scenarios.
Comparing different workloads
Intuitively the impact of network regression (including latency, packet loss etc.) is different in the above scenario, gRPC stream has no regression when having 75ms latency, while MySQL execution throughput drops a lot. In this section I will compare several workloads under network regression. The experiment was conducted on several servers in one IDC, and the network regression was simulated by chaosd. I simulated the network latency and packet loss, which are the most common network regression in the real world. The simulated workloads are as follows:
The first one is a simple sysbench insert workload, writing data to 32 tables in MySQL directly with 32 sysbench threads.
The second one is to simulate a gRPC bidirectional stream between client and server, the client starts N workers, each one sets up a gRPC stream and receives data from gRPC server. The client will collect received data and report throughput every 10 seconds. The benchmark code can be found in grpc-test.
The third one is another MySQL usage scenario, but it has elastic workers compared to sysbench workload. Elastic worker means when the write to MySQL is slow, the program will spawn more workers to write to MySQL. Each worker writes simple insert SQL to MySQL, and there is no wait condition among workers, which means the worker can run concurrently and transactions in MySQL have no lock contention. The benchmark code can be found in elastic_mysql, besides the max pending workers in this experiment is
worker size * max pending per worker = 20 * 120 = 2400.
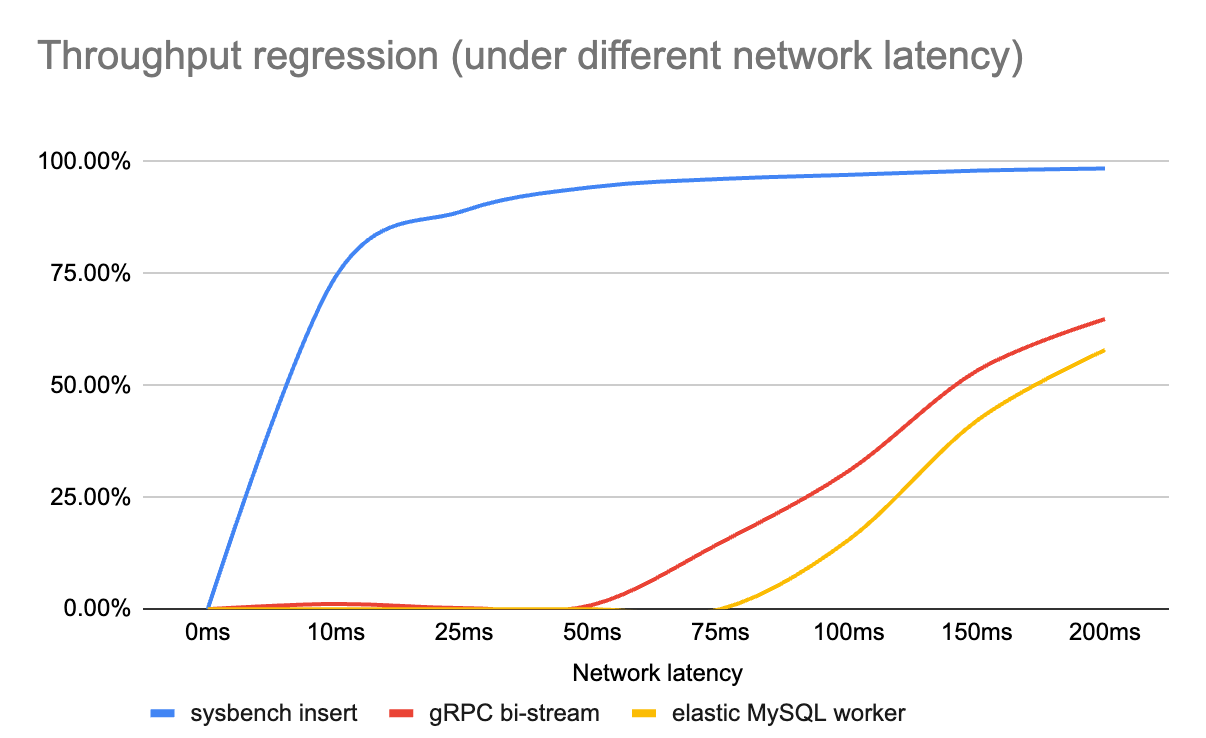
The benchmark result is as follows, note the absolute value of throughput is not essential, but we should pay attention to the throughput change when network regression happens.
| Network latency | 0ms | 10ms | 25ms | 50ms | 75ms | 100ms | 150ms | 200ms |
|---|---|---|---|---|---|---|---|---|
| sysbench insert | 10732 | 2741 | 1170 | 603 | 408 | 309 | 208 | 157 |
| gRPC bi-stream | 42.4M | 41.9M | 42.3M | 42.0M | 36.1M | 29.3M | 19.8M | 14.9M |
| elastic MySQL worker (qps/pending workers) | 4000/0 | 4000/80 | 4000/205 | 4000/420 | 4000/780 | 3380/2353 | 2314/2385 | 1682/2392 |
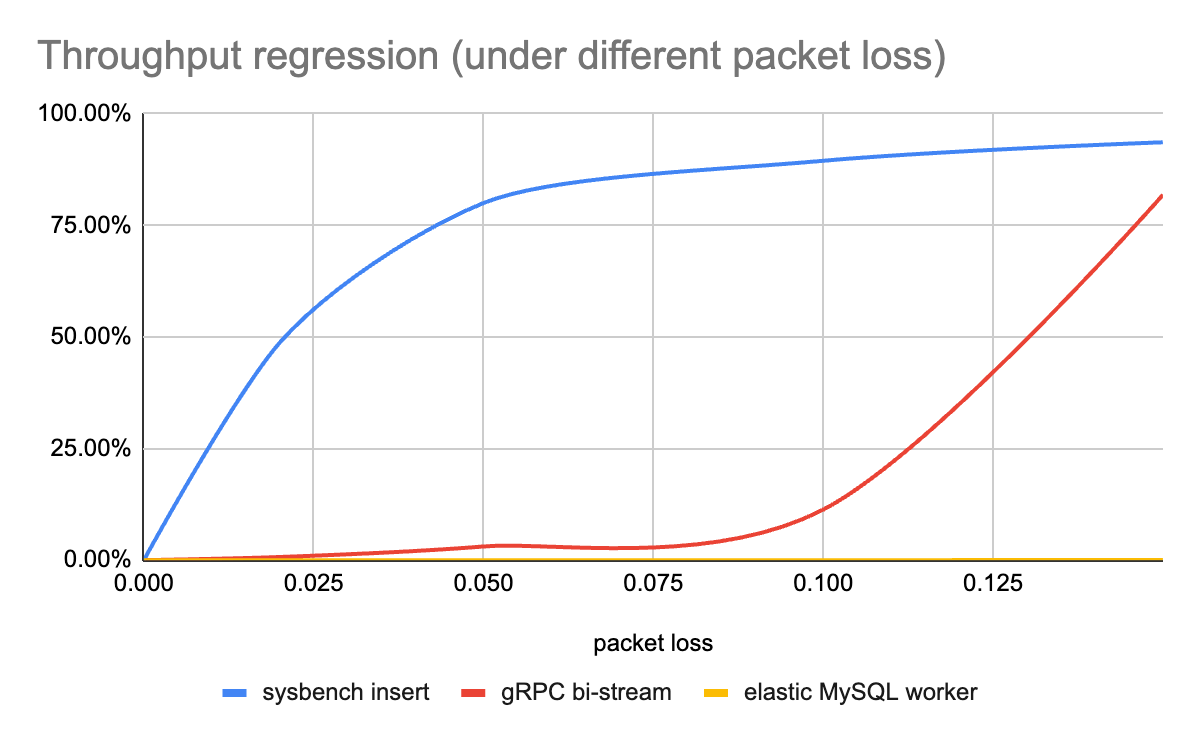
| packet loss | 0 | 2% | 5% | 10% | 15% |
|---|---|---|---|---|---|
| sysbench insert | 10732 | 5502 | 2145 | 1129 | 684 |
| gRPC bi-stream | 42.4M | 42.1M | 41.1M | 37.6M | 7.7M |
| elastic MySQL worker (qps/pending workers) | 4000/0 | 4000/20 | 4000/62 | 4000/156 | 3999/297 |
In addition to the absolute value of throughput, the jitter of throughput is another important factor of service quality. Given the gRPC bi-stream and network loss scenario, we run each test for 10 minutes, observe throughput every 5 seconds and calculate the standard deviation divided by average throughput of these points to measure the throughput stability, and the test result is as follows.
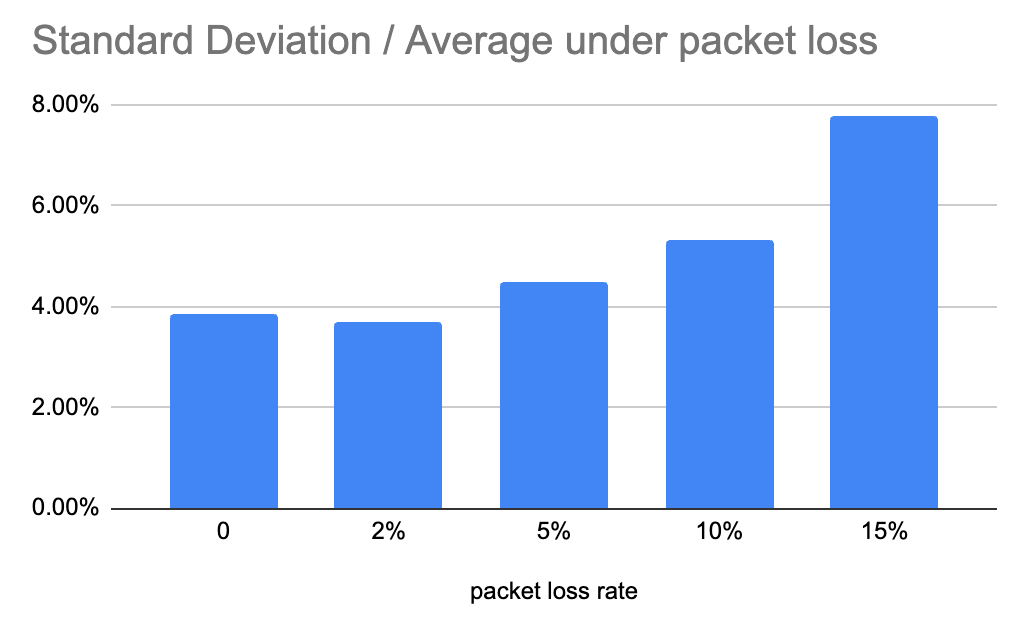
It is easy to draw some conclusions from the above benchmark result
The network regression(either latency or packet loss) impact on throughput in sysbench workload is significant. As for the reasons, in sysbench workload the throughput is decided by the thread count (which is a fixed number and configured by
--threadswhen running sysbench) and throughput of a single thread. Each single thread executes transaction serially in a loop until meeting some exit condition(ref: internal/sysbench.lua:thread_run). So in the sysbench workload, when response from MySQL is slowed down by network regression, the worker thread will waste a lot of time waiting for SQL execution response and leads to severe regression of throughput.The network regression impact on throughput in gRPC bi-stream workload is not significant, which is achieved by the throughput optimization on high latency connections. gRPC-go implements a BDP estimation and dynamic flow control window feature. This feature calculates the current BDP (Bandwidth Delay Product (BDP) is the bandwidth of a network connection times its round-trip latency. This effectively tells us how many bytes can be “on the wire” at a given moment, if full utilization is achieved) and bandwidth sample and decides if the flow control windows should go up (algorithm). There exists a long issue(grpc-go issue#1043) that discusses this topic, which deserves to take a look.
The network regression has no impact on throughput in elastic worker workload when the worker doesn’t reach the upper limit. Since more workers can be spawned when some pending executions are not returned, the SQL execution bandwidth (from the point view of server side) will be fully used, without time wasted in waiting for response to arrive at the client side. Compared with the gRPC scenario, the elastic worker is another kind of dynamic window.
Note we can’t achieve performance optimization by increasing worker size or buffer size infinitely. For example in the elastic MySQL worker scenario, when MySQL worker count increases, more lock contention will happend in either client side (more workers lead to heavy workload of runtime) or server side (more transactions lead to more lock conflicts). This can be treated as a kind of bufferbloat. Known reasons for performance drawbacks include:
- More lock contention will happen in either the client side (more workers lead to heavy workload of runtime) or server side (more transactions lead to more lock conflicts).
- More clients wait for response from server side leads to longer latency, more waiting clients could cause connection reset by peer because of timeout.
Potential solutions to increase throughput
Coming back to the scenario that is mentioned at the beginning of the article, our solution is to put the data transfer service in the same region with the downstream MySQL, but whether there exists other solutions? There may or may not, which is based on the cost of system modification, this section will talk about two potential solutions, one solution is to relay the data via a suitable protocol, and the other one is trying to tune the network via some networking tunnel.
The relay service solution
This solution is straightforward, it still deploys data transfer service in the upstream region, but it doesn’t execute SQLs directly to downstream MySQL, instead it works as a relay service, it works as a gRPC server that serves gRPC stream with translated SQLs, in the downstream we deploy another consumer service to receives translated SQLs from the relay service, and the consumer writes SQLs to the downstream MySQL. This solution has several advantages, as well as several disadvantages
- Advantages
- Reduce throughput loss with the help of good performance of gRPC on high latency network.
- Reduce network bandwidth between upstream and downstream regions, because the data transferred is the minimal SQL data.
- Disadvantages
- Long data links will introduce larger latency.
- More components will introduce more costs, both in development and system maintenance.
Tuning the network with tunnel
kcptun is a tunnel based on KCP with N:M multiplexing and FEC(Forward error correction) for transfer error correction. KCP can achieve the transmission effect of a reduction of the average latency by 30% to 40% and reduction of the maximum delay by a factor of three, at the cost of 10% to 20% more bandwidth wasted than TCP. kcptun can be used in some cross-region scenarios to accelerate TCP stream, in order to verify whether kcptun can help the above scenario, I test the sysbench workload with kcptun again. The basic topology is as follows

| 0-100ms | 0-50ms | 0-25ms | 0-10ms | 100ms | 50ms | 25ms | 10ms | |
|---|---|---|---|---|---|---|---|---|
| Direct write | 969 | 2199 | 3875 | 6274 | 309 | 603 | 1160 | 2716 |
| Write via kcptun | 3730 | 4967 | 5395 | 5948 | 308 | 596 | 1145 | 2613 |
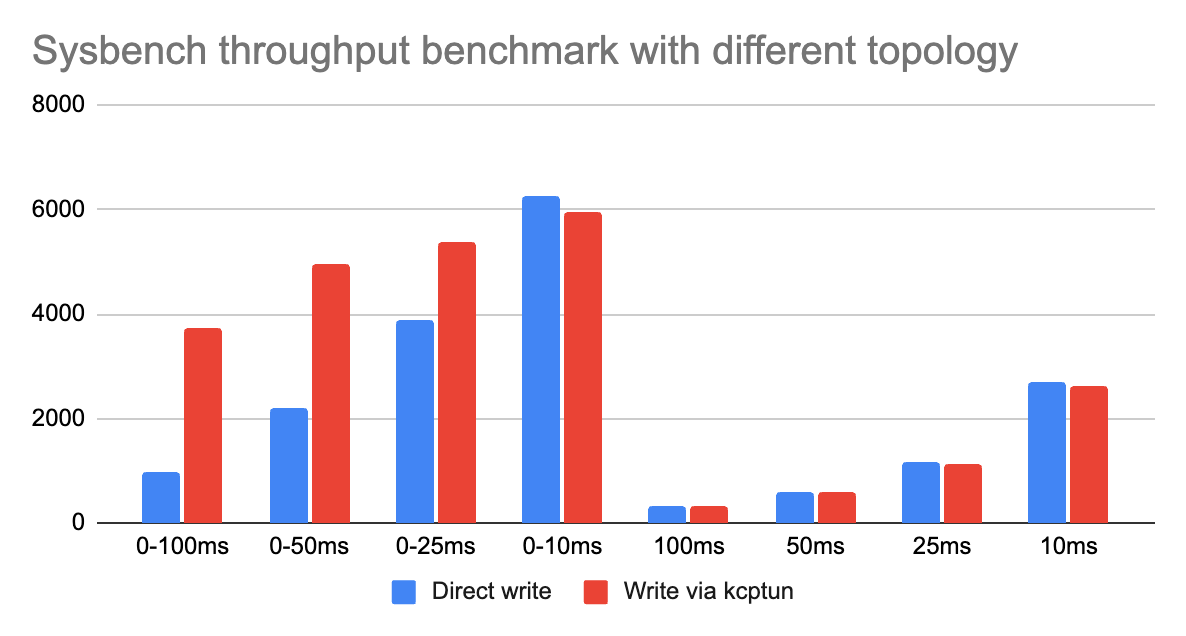
From the benchmark result, we can see if the network has a fixed latency, kcptun doesn’t make any sense to improve throughput, even a little regression. On the other hand, if the latency of network is not stable, the larger latency jitter exists, the higher throughput improvement will be gained with kcptun. Considering the network situation and the overhead of KCP encoding/decoding, this strategy is not a silver bullet but can improve performance in part of scenarios.
Advices about system performance
- The performance of a system should be estimated. It is important to abstract the architecture and estimate the performance indicators based on known knowledge.
- If the estimation is beyond precocious, try to write a minimal demo to simulate the workload.
- The deployment topology is worth thinking deeply before running the system in a production environment.
- There always exist tradeoffs in software systems, we can add enough metrics to the system and tune the performance and resource usage dynamically.
Remaining problems
There still exist many topics that have not been discussed in this article, such as
- In real word, when the performance of a network service drops or jitter happens because of network regression, is there any way to diagnose network conditions quickly or even find the problems before it affects the service and adopt some strategies to reduce the impact. For example
- In the gRPC scenario, is there any gRPC metric to show the flow control window size, message buffer size that can help to monitor the gRPC running status.
- In the MySQL scenario, how to measure whether the bandwidth of client side and server side is busy or free.
- In real world network regression is not a decline of a single indicator, it may be multifactor functioning and how to evaluate the network regression is a big topic. A related article: network quality monitoring in Linux kernel.
- This article only talks about the network regression affections to MySQL protocol and gRPC streaming(HTTP/2 underlying), there are many commonly used protocols that have not been discussed, such as HTTP/1.1, WebSocket etc.