A brief introduction to BIDE algorithm
背景
最近在做的数据库活动检测引擎,要实现一个异常行为检测的模块。简单的说异常行为检测就是先确定描述用户访问数据库的行为模型,然后定义一系列描述正常访问数据库的行为,检测过程中一旦用户行为与正常行为轮廓不符,则被认定为攻击行为。在实际系统中,正常行为轮廓会组成正常行为知识库,这个知识库会很大,所以正常行为轮廓不能简单的人工定义,于是一个自动挖掘正常行为知识库的需求被提了出来。
在系统实现过程中,会将用户对数据库产生影响的原子性操作,比如一次select,一次update抽象成为一个item,用户访问数据库的一系列行为可以抽象成为一个item的序列,由此引出了通过频繁序列挖掘来获得正常行为知识库的想法。
频繁序列挖掘
在介绍频繁序列挖掘之前先简单说一下关联规则挖掘,关联规则挖掘用于从大量数据中挖掘出有价值的数据项之间的相关关系。关联规则解决的常见问题如:“如果一个消费者购买了产品A,那么他有多大机会购买产品B?”以及“如果他购买了产品C和D,那么他还将购买什么产品?”。(引自维基百科),关联规则挖掘领域最著名的故事就是啤酒和尿布的故事了,比较经典的算法有Apriori,Eclat,FP-Growth等。
频繁序列挖掘(Sequence Mining)与关联规则挖掘类似,不同的是序列挖掘结果的各个项目之间是有序的。早期比较著名的序列挖掘算法有GSP,SPADE,PrefixSpan,BIDE算法是2004年被提出,它极大地提高了序列挖掘的性能。这里有一篇对各种序列挖掘算法详分析对比的论文:Frequent pattern mining: current status and future directions
BIDE算法的实现描述
提出BIDE算法的论文:BIDE:efficient mining of frequent closed sequences,下面按照论文中的一个例子对算法进行简单的介绍。
序列集合
| Sequence identifier | Sequence content |
|---|---|
| 1 | CAABC |
| 2 | ABCB |
| 3 | CABC |
| 4 | ABBCA |
frequent sequences
- A:4, AA:2, AB:4, ABB:2, ABC:4, AC:4, B:4, BB:2,BC:4, C:4, CA:3, CAB:2, CABC:2, CAC:2, CB:3, CBC:2,CC:2
frequent closed sequences
- AA:2, ABB:2, ABC:4, CA:3, CABC:2,CB:3
搜索树:
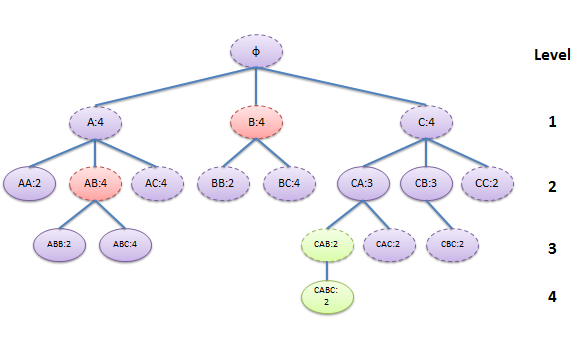
一些背景知识:
- 支持度:有绝对支持度和相对支持度两种,相对支持度是绝对支持度除以总序列数。上表中A,B,C为独立的项(item),不同item的组合形成一个序列,如果序列a中的每个item都在序列b中出现,并且是保序的,那么a是b的子序列。序列数据库(SDB)包含一些序列,一个序列a的所有父序列的总数目即为序列a在SDB中的绝对支持度,简单的说一个序列的支持度就是序列在SDB中出现的次数(在同一条序列中多次出现只记一次)。比如在上表中,A在CAABC中出现2次,计算支持度时只记1。
- 最小支持度:挖掘时候需要定义的常量,支持度大于最小支持度的序列被认为是频繁序列。
- 闭序列:序列可以进行扩展,比如上表序列1中包括序列CAB,可以扩展成为CABC。如果一个序列的支持度和它的一个扩展序列的支持度相等,那么这个序列就不是闭序列。反之,如果一个序列找不到一个扩展,使得扩展序列支持度与原序列支持度相等,那么这个序列就是闭序列。
算法要点
1. 利用BackSpan search space Pruning减少不必要的搜索过程。比如在搜索树中,B开头的序列都会被AB开头的序列包含,所以以B开头的子树可以不用搜索。
2. 利用forward-extension 和 backward extension 检测一个序列是否为闭序列,如果不是闭序列则不会包含在结果集中。
总结
BIDE算法的高效体现在两个方面:一是挖掘过程中不需要产生临时的频繁项集,这极大的节约了存储空间;另一方面由于算法只挖掘频繁闭序列,挖掘过程中会减少很多非闭序列的挖掘过程。这两点加起来使得BIDE算法在性能上有了很大的提升。